邢波再出手:上次「骂」完世界模型,这次轮到智能体了
邢波再出手:上次「骂」完世界模型,这次轮到智能体了去年夏天,MBZUAI 校长、CMU 教授邢波一篇《世界模型批评》吸引了研究社区广泛关注,他从科幻经典《沙丘》里「完美模拟现实」的想象出发,逐一拆解了当下几大世界模型流派的硬伤,提出了一套新架构,也由此引出了他与 Yann LeCun 之间一场关于「世界模型到底该怎么造」的公开辩论。
来自主题: AI技术研报
6732 点击 2026-07-01 15:43
 搜索
搜索
去年夏天,MBZUAI 校长、CMU 教授邢波一篇《世界模型批评》吸引了研究社区广泛关注,他从科幻经典《沙丘》里「完美模拟现实」的想象出发,逐一拆解了当下几大世界模型流派的硬伤,提出了一套新架构,也由此引出了他与 Yann LeCun 之间一场关于「世界模型到底该怎么造」的公开辩论。

Yann LeCun的JEPA架构很可能不会work,但至少证明了隐空间比像素或文本空间具备更强的泛化能力;

世界模型(World Model),正在成为AI领域新的技术高地。从OpenAI的Sora,到图灵奖得主Yann LeCun力推的JEPA体系,再到李飞飞创办的World Labs,全球最顶尖的一批研究者都在试图回答同一个问题:AI究竟如何像人一样理解世界,而不仅仅是生成语言和图像。

“LLM 就是一条死路。”
1天前,2026年4月,Primepoint完成了$10M种子轮融资。对一家成立仅两年、团队不足10人的公司而言,这个数字不算小。更值得关注的是投资人结构:深度学习先驱Yann LeCun亲自下注,多家专注建筑科技的头部VC联合跟投。

3 月 10 日,APPSO 中文独家获悉,世界模型研究所/创业公司 AMI 已完成 10.3 亿美元融资,投前估值 35 亿美元。该公司由图灵奖得主、前 Meta 首席 AI 科学家杨立昆 (Yann LeCun) 创办。

基础模型时代,大模型能力的爆发,很大程度上源于在海量文本上的预训练。然而问题在于,文本本质上只是人类对现实世界的一种抽象表达,是对真实世界信息的有损压缩。
离开Meta这座围城后,Yann LeCun似乎悟了“不要把鸡蛋装在同一个篮子里”。一边,他亲手打造了自己的初创公司AMI,试图在世界模型这条赛道上大展拳脚;同时,他的目光又投向了硅谷的另一角。
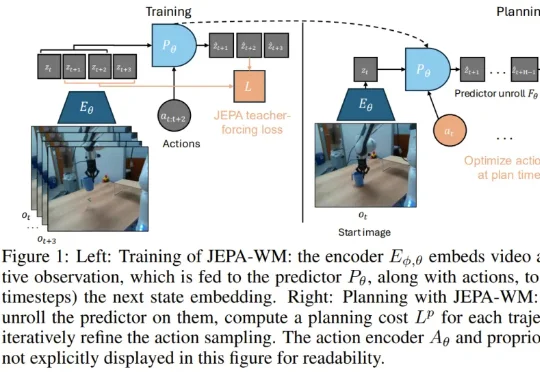
真正的挑战在于,如何在错综复杂的原始视觉输入中提取抽象精髓。这便引出了本研究的主角:JEPA-WM(联合嵌入预测世界模型)。从名字也能看出来,这个模型与 Yann LeCun 的 JEPA(联合嵌入预测架构)紧密相关。事实上也确实如此,并且 Yann LeCun 本人也是该论文的作者之一。

知名AI 科学家LeCun周四证实, 他已创办一家新创企业 ——这是科技界人尽皆知的秘密——但他表示不会以首席执行官身份运营这家新公司。